持续更新
lab待更新
操作系统概论
历史
基础概念
abstraction
• Threads abstract the CPU.
• Address spaces abstract memory.
• Files abstract the disk.
• Processes abstract of the computer.
• Input/Outputs abstract the devices
抽象是简化复杂事务,虚拟化是凭空创造不存在的东西
文件描述符
文件描述符在形式上是一个非负整数。 实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。 当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。 在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。
文件类型:普通文件(包含用户信息的文件,用户可以对这些文件进行各种操作-添加、修改、删除等),目录文件(包含文件名列表和这些文件相关的其他信息),特殊文件(设备文件,device files,printers,tapes)
计算机启动
加电置固定指令地址,执行BIOS固件自检,加载mbr,loader在其中被成功加载,loader加载kernel
• —> Start BIOS (Basic Input Output System)
• —> Check the RAM and basic devices, e.g., keyboard
• —> Scan the PCIe and PCI buses to detect all the
other devices.
• —> Select boot device from CMOS
• —> The boot loader starts to find the OS
• —> OS is loaded, configures necessary information,
and gets the control of the computer
保护
cpu保护
memory保护
中断保护
系统调用
中断处理
实模式和保护模式
8086内置4个段寄存器(代码段CS,数据段DS,堆栈段SS,附加段ES),每个段寄存器可以存放一个16位的段地址,在寻址时,处理器首先将段地址左移4位,然后再加上偏移地址,由此得到20位的物理地址(如 1234H:5678H所对应的物理地址为12340H+5678H=179B8H,其中, 1234H:5678H称作逻辑地址或虚地址)。当地址有溢出时(FFFFH:FFFFH 对应的物理地址是FFFF0H+FFFFH=10FFEFH,大于FFFFFH),会发生回卷(10FFEFH = FFF0H)。
如此寻址会产生很多问题。一个段大小最大为2^16=64KiB,并且,所有的段都是可读写的。这意味着不同的段存在着重叠部分(即不同的逻辑地址可以映射到相同的物理地址),无法保证程序的安全性(程序段可被修改),也不具有权限分级(大家都有读写权限,另,那时真的有权限这个概念么)。
在实模式中,段寄存器保存的是段首地址(左移4位以后),而在保护模式,其中保存的内容称作选择器(selector),其本质是索引(13位,即在表中的偏移量)加TI位(1位,表示是使用GDT还是LDT)和优先级信息(2位,0~3值越小优先级越高)。
在寻址时,首先拿出选择器(段寄存器)的高13位作为偏移量(索引),结合TI位找到描述符。取出其中24位长的段首地址信息,再加上偏移量(这个偏移量是段地址:偏移量 中的偏移量,前面提到的描述符表的偏移量是段地址的高13位),得到实际物理地址。
简单来说,286保护模式下的寻址步骤是:拿到段寄存器高14位(13+1),查描述符表,得到24位段地址,加上偏移量,得到物理地址。当然,其中还有保护机制,这里没有说明。
段选择子存在段寄存器中,16位=13位index+1位TI+2位privilege,TI -table indicator位表示该段选择子为全局段还是局部段,RPL 表示该段选择子的特权等级,13位Index表示描述符表中的编号(下标),拿index去段描述符表找段描述符,根据段描述符结构找段基址加偏移量即可。
顶级会议期刊
会议
(SOSP) ACM Symposium on Operating Systems Principles
(OSDI) USENIX symposium on Operating Systems Design and Implementation
(ASPLOS) ACM International Conference on Architectural Support for Programming
Languages and Operating Systems
(ATC) USENIX Annual Technical Conference
(FAST) USENIX Conference on File and Storage Technologies
(Eurosys) Proceedings of the European Conference on Computer Systems
(NSDI) USENIX Symposium on Networked Systems Design and Implementation
(ISCA) International Symposium on Computer Architecture
(MICRO) International Symposium on Microarchitecture
期刊
(TOCS) ACM Transactions on Computer Systems
(OSR) ACM SIGOPS Operating Systems Review
(TOC) IEEE Transactions on Computer
(TPDS) IEEE Transactions on Parallel and Distributed Systems
进程
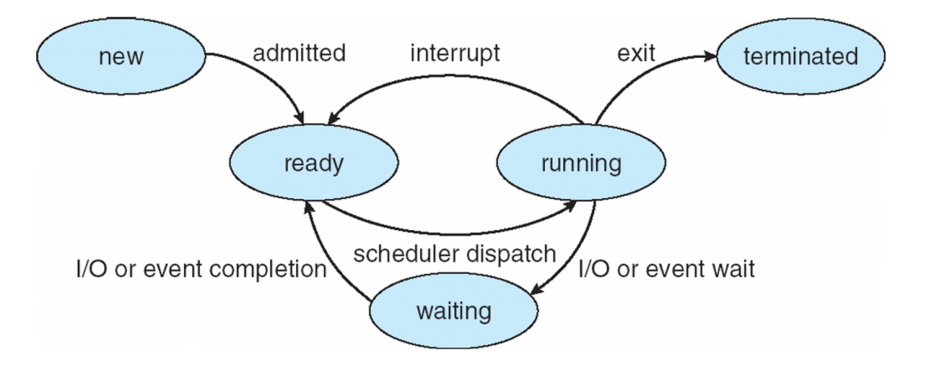
进程状态
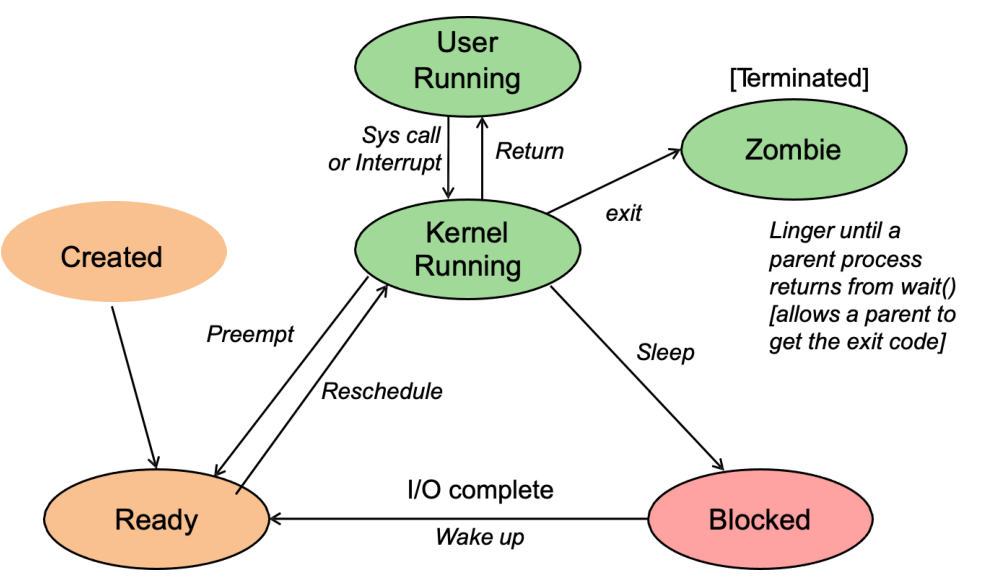
R(TASK_RUNNING,可执行状态),这个进程是可运行的——要么它正在运行,要么在运行队列中等待运行;S(TASK_INTERRUPTIBLE,中断状态),这个状态的进程因为等待某事件的发生(比如等待socket连接、等待信号量等)而被挂起,然后当这些事件发生或完成后,对应的等待队列中的一个或多个进程将被唤醒。D(TASK_UNINTERRUPTIBLE,不可中断状态),在进程接收到信号时,不会被唤醒变成可运行的。除了这一点,该状态和TASK_INTERRUPTIBLE其他部分完全一样,这个状态通常用于进程必须不间断等待或者事件发生的频率很快,并且无法用kill命令关闭处于TASK_UNINTERRUPTIBLE状态的进程。T(TASK_STOPPED或TASK_TRACED,暂停状态或跟踪状态),该状态表示该进程已经停止执行,并且不具有再次执行的条件。向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。而当进程正在被跟踪时,它处于TASK_TRACED状态。Z(TASK_DEAD或EXIT_ZOMBIE,退出状态),进程在退出的过程中,处于TASK_DEAD状态,如果它的父进程没有收到SIGCHLD信号,故未调用wait(如wait4、waitid)处理函数等待子进程结束,又没有显式忽略该信号,它就一直保持EXIT_ZOMBIE状态。只要父进程不退出,这个EXIT_ZOMBIE状态的子进程就一直存在,这也就是所谓的”僵尸”进程。X(TASK_DEAD - EXIT_DEAD,退出状态),进程即将被销毁。EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
对应状态码
| 状态 | 定义 |
|---|---|
| R | Running.运行中 |
| S | Interruptible Sleep.等待调用 |
| D | Uninterruptible Sleep.等待磁盘IO |
| T | Stoped.暂停或者跟踪状态 |
| X | Dead.即将被撤销 |
| Z | Zombie.进程已经结束,仅映像名留存,所谓的僵尸进程 |
| W | Paging.内存交换 |
| N | 优先级低的进程 |
| < | 优先级高的进程 |
| s | 进程的领导者 |
| L | 锁定状态 |
| l | 多线程状态 |
| + | 前台进程 |
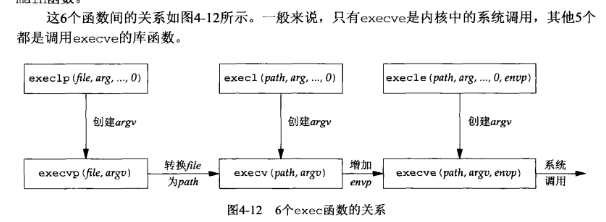
fork和exec
父进程中调用fork之前打开的所有描述符在fork返回之后由子进程分享。我们将看到网络服务器利用了这个特性:父进程调用accept之后调用fork。所接受的已连接套接字随后就在进程与子进程之间共享。通常情况下,子进程接着读写这个已连接套接字,父进程则关闭这个已连接套接字。
fork的两个典型用法:
(1)一个进程创建一个自身的副本,这样每个副本都可以在另一个副本执行其他任务的同时处理各自的某个操作。这是网络服务器的典型用法。
(2)一个进程想要执行另一个程序。既然创建新进程的唯一方法是调用fork,该进程于是首先调用fork创建一个自身的副本,然后其中一个副本(通常是子进程)调用exec把自身替换成新的程序。这是诸如shell之类程序的典型用法。
fork() 函数用于创建一个新的子进程,该子进程几乎复制了父进程的全部内容,但是,这个新创建的子进程如何执行呢?exec 函数族就提供了一个在进程中启动另一个程序执行的方法。它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新的进程替换了。另外,这里的可执行文件既可以是二进制文件,也可以是Linux下任何可执行的脚本文件。
pid=fork()后,父进程中pid>0,子进程pid=0
在 Linux 中使用exec函数族主要有两种情况:
● 当进程认为自己不能再为系统和用户做出任何贡献时,就可以调用 exec 函数族中的任意一个函数让自己重生。
● 如果一个进程想执行另一个程序,那么它就可以调用 fork() 函数新建一个进程,然后调用 exec 函数族中的任意一个函数,这样看起来就像通过执行应用程序而产生了一个新进程(这种情况非常普遍)。
exec函数族的6个函数的区别在于:(a)待执行的程序文件是由文件名(filename)还是由路径名(pathname)指定;(b)新程序的参数是一一列出还是由一个指针数组来引用;(c)把调用进程的环境传递给新程序还是给新程序指定新的环境。
事实上,这6个函数中真正的系统调用只有execve(),其他5个都是库函数,它们最终都会调用execve()这个系统调用。在使用exec函数族时,一定要加上错误判断语句。exec 很容易执行失败,其中最常见的原因有:
① 找不到文件或路径,此时 errno 被设置为 ENOENT。
② 数组argv 和envp 忘记用NULL结束,此时,errno被设置为 EFAUL。
③ 没有对应可执行文件的运行权限,此时 errno 被设置为EACCES。
这些函数只有在出错时才返回到调用者,否则,控制将被传递给新程序的起始点,通常就是main函数。

exec可以更改和继承的包括以下单不限于以下的上下文内容:
• File descriptors
• User/group ID
• Process group and session IDs
• Current directory
• Resource limits
• Scheduling priority and affinity
IDLE进程
没有处于RUNNABLE状态的进程时切换至内核IDLE进程,该进程调⽤ waitForInterrupt() 执⾏ hlt 指令, hlt 会使得CPU进⼊暂停状态,直到外部硬件中断产⽣
执⾏流在bootloader中加载并跳转到内核, 然后执⾏⼀系列 的初始化⼯作,等到初始化结束后将会打开中断,此时执⾏流摇身⼀变,成为了实验中 的IDLE进程,等待中断的到来
static inline void waitForInterrupt() {
asm volatile("hlt");
}
...
while(1) {
waitForInterrupt();
}Modeling Multiprogramming
多道程序设计模型
进程调度
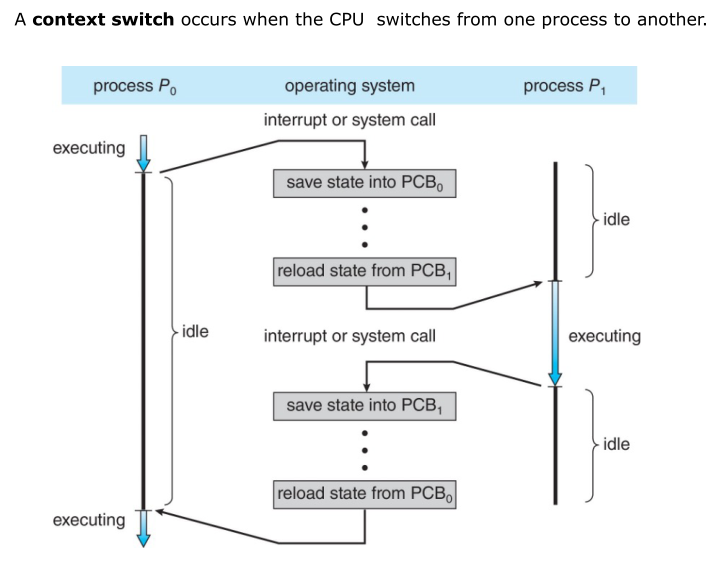
context switch & CPU switch
进程间通信
interprocess communication
典型进程间通信模式
- 生产者-消费者模式
- 生产者只写,消费者只读
- 缓冲区无限大时:生产者不停写,消费者只在缓冲区存在内容时读
- 缓冲区有限大:生产者在缓冲区未满时写,消费者只在缓冲区存在内容时读
两种通信方法:
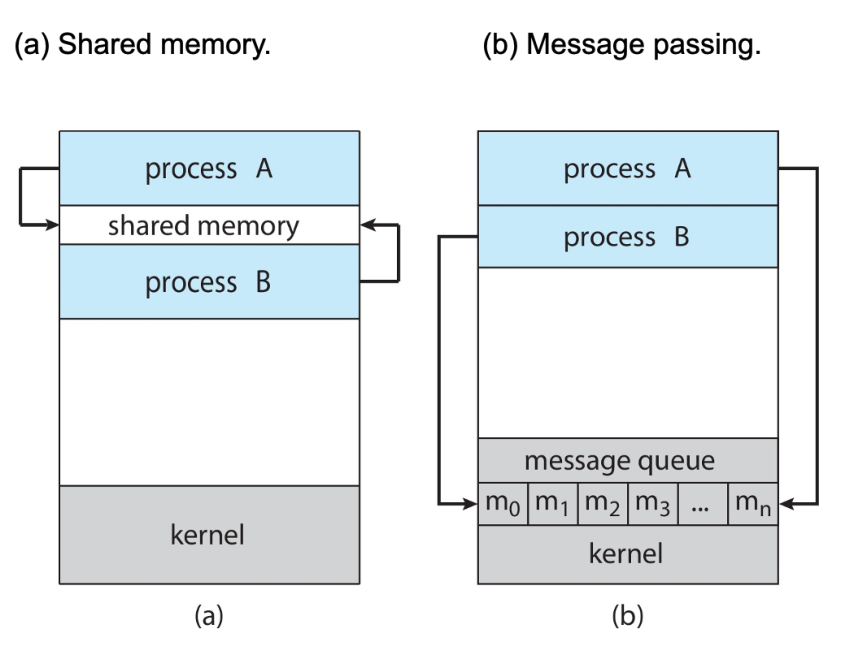
共享内存
通信由用户程序控制而非操作系统,难点在于内存一致性(同步)
可用循环数组和两个逻辑指针来表示
item next_produced; while (true) { /* produce an item in next produced */ while (((in + 1) % BUFFER_SIZE) == out) //buffer full ; /* do nothing */ buffer[in] = next_produced; in = (in + 1) % BUFFER_SIZE; } item next_consumed; while (true) { while (in == out) //buffer empty ; /* do nothing */ next_consumed = buffer[out]; out = (out + 1) % BUFFER_SIZE; /* consume the item in next consumed */ }或者用个计数器counter(不能循环)
race condition
竞争危害/条件,在计算机系统中实现时,可能会因为生产者与消费者采用不同寄存器短时间内调取同一counter值增加和减少而产生counter的错误修改,但第一种方法不会产生这种危害,两个process的工作是解耦的,没有counter联系
消息传递
建立通信链接(
•Hardware bus
•Network
•Shared memory),通过send/receive传递信息直接通信:•send (P , message) – send a message to process P
•receive(Q, message) – receive a message from process Q
链接自动建立,一个链接对应一对通信进程间接通信:mailboxes (also referred to as ports),共享特定端口通信,端口可关联多个进程,每对进程可共享多个通信链路
链路均可全双工,也可半双工
阻塞(同步,发送后等待收到才再次发送),非阻塞(异步,send and continue),可搭配组合,接收发送全阻塞时可称为rendezvous(约定)
异常情况
比较:内存共享更快,消息传递需要重复sys调用,但消息传递在分布式系统中更容易实现,不用考虑内存冲突、一致性问题,适用于交换少量数据,多核系统中也更实用
例子:POSIX-内存共享,sockets,pipes,named pipes ,signals
线程
概念
fork() 等同于 clone(2),2代指SIGCHILD
pthread_atfork(3)
Native POSIX Thread Library (NPTL), a Linux implementation of POSIX thread library
线程是代表一个独立、可调度任务的一个可执行指令序列的抽象
motivation and usage
解决MTAO(multiple things at once)
操作系统提供的并发单位,抽象来说就是并发(concurrency)机制的体现
并发不一定并行(parallelism),但是并行一定并发
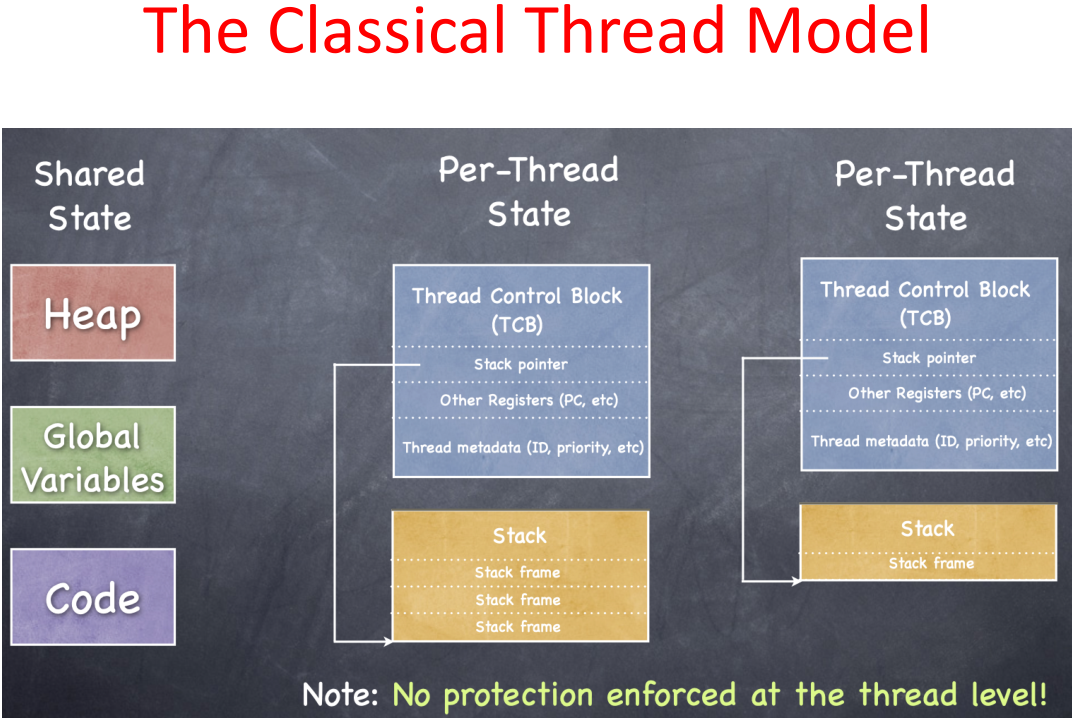
semi-process,轻型进程,不同线程共享地址空间,共享所有数据
model
一个进程中所有线程共享的item: address space,global variables,open files ,child processes,pending alarms(未决警报),signals and signal handlers,accounting info
线程单独享有item: program counter(pc),registers,stack,state
/*basic options*/
thread_create(thread, func, arg)
//creates a new thread in thread, which will execute function func with arguments arg.
thread_yield()
//calling thread gives up the processor.
thread_join(thread)
//wait for thread to finish, get the value thread returned.
thread_exit(ret)
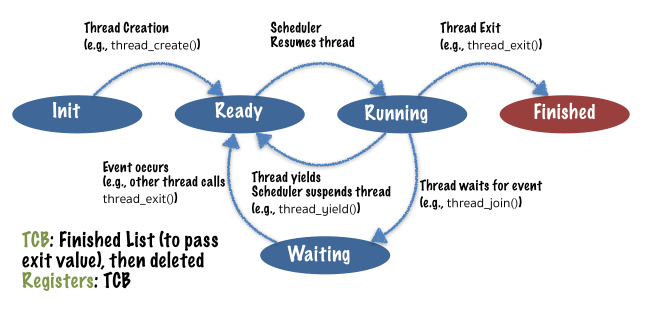
//quit the current thread and clean up, make ret available to any successful join (wait for this thread). TCB(thread control block)
五个状态:
init
TCB: Ready List
Registers: In TCBready
TCB: Ready List
Registers: In TCBTCB: Running List
Registers: Processorrunning
TCB: Running List
Registers: Processorwaiting
TCB: Synchronization waiting list
Registers: TCBfinished
TCB: Finished List (to pass exit value), then deleted
Registers: TCB
POSIX

Implementation
user-level: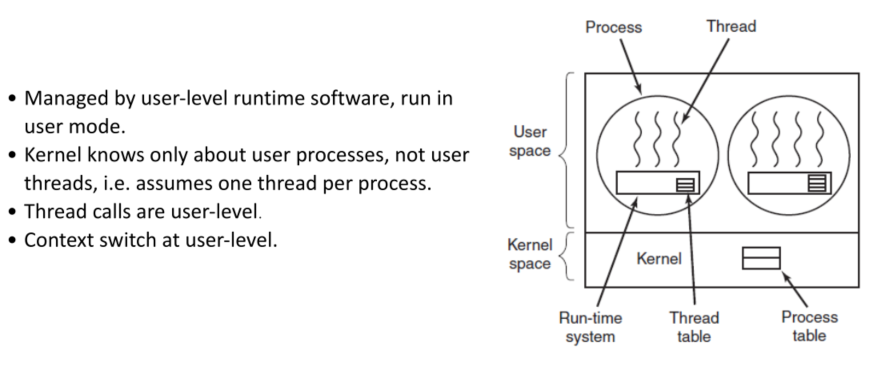 thread call,context switch均在user-level,快、可用户自定义调度线程、kernel复杂度低,kernel 单线程;
thread call,context switch均在user-level,快、可用户自定义调度线程、kernel复杂度低,kernel 单线程;
缺点在于一个线程阻塞,整个进程阻塞,kernel只能做次优化决策( OS modifications to overcome this. ),没有时间中断,当一个进程运行只能yield/exit,其它线程才能切入执行
kernel-level: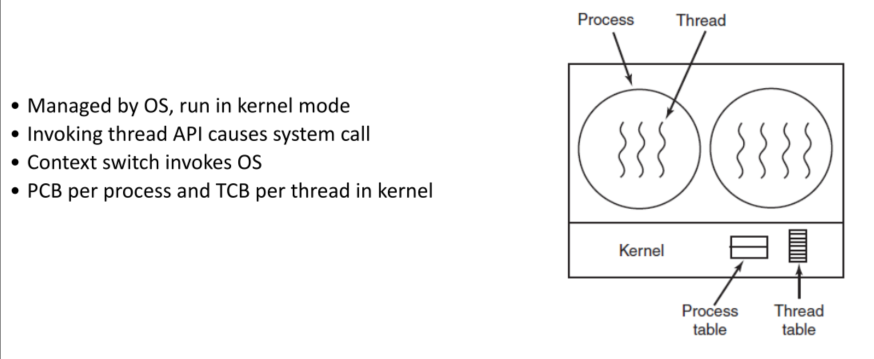
内核能掌控线程信息,实现更好调度等优化,当线程频繁阻塞时很重要
缺点在于 High overhead ,OS更复杂
hybrid: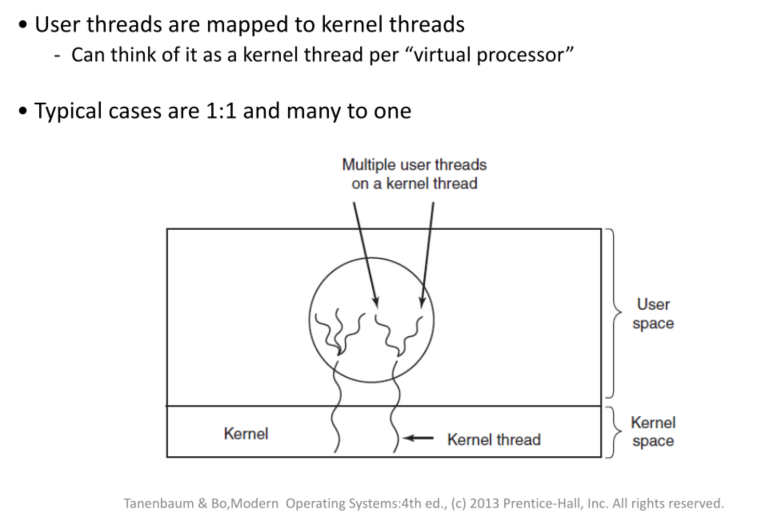
1对1,多对一
context switch in kernel threads:
thread running->switch to kernel->save thread state to TCB->choose new thread(policy decision left to scheduler)->load thread state from TCB->thread running
引起上下文切换的可能:内部系统调用/异常,外部中断
context switch in user threads:
没有操作系统支持
•TCBs,就绪列表,完成列表,等待列表-在用户空间
•线程库调用只是过程调用
有OS支持:
•使用上行调用(upcalls)虚拟化中断和异常
•使用系统调用注册一个信号处理程序(signal handler)
•中断时,内核暂停进程执行,保存进程P状态并运行内核处理器;完成后:
•将P的保存状态复制到P的信号堆栈中
•在信号处理程序中恢复P的执行(load state with PC = &signal_handler;SP -> state on stack)
•信号处理器将状态从堆栈移动到TCB
•在就绪列表中恢复其他一些TCB的状态
Pop-Up
使用这种弹出式线程的优点是每个新请求都将被快速处理,几乎是即时的(这取决于服务器的当前负载)。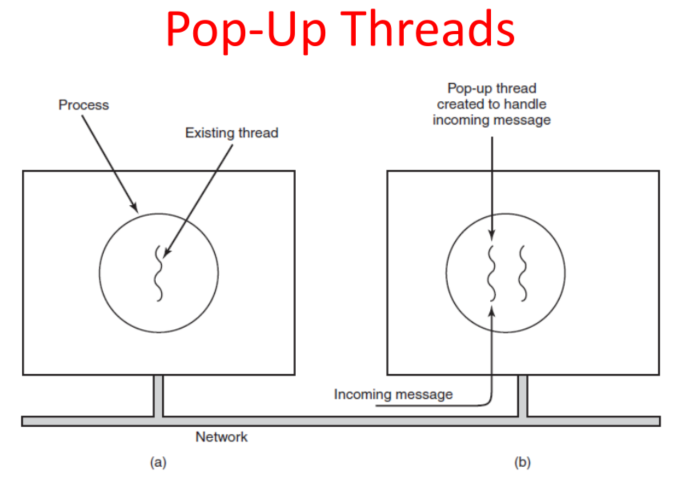
To see thread informationps -m
ps m –o pid,tid,command
调度
简介
Simplified view of scheduling:
- Save process state (to PCB)
- Pick a process to run next
- Dispatch process
调度时机
1.新进程产生
2.进程死亡并返回exit状态
3.进程阻塞
4.I/O 中断
5.时钟中断,例-抢占式调度程序使用它来替换正在运行的进程
调度算法类别
抢占式/非抢占式
- Batch.
- Interactive.
- Real time
调度算法目标
总的来说:公平性,cpu高利用率
针对不同的系统又有不同的要求
不同系统下的调度
批处理系统调度
• First-Come First-Served
• Shortest Job First
• Shortest Remaining Time Next
交互式系统调度
• Round-Robin Scheduling
• Priority Scheduling
• Multilevel Queues
• Multilevel Feedback Queue
• Guaranteed Scheduling
• Lottery Scheduling
实时系统调度
Time plays an essential role
- having the right answer but having it too late is
often just as bad as not having it at all.
策略和机制
线程调度
例子
评估
同步
简介
进程/线程同步(并发控制)和数据同步(数据一致性,完整性)
为什么需要同步?
- 线程调度不确定,每次运行程序都可能产生不一样的情况,比如出现不同的并发情况,调度器做出不同决策,cpu以不同频率运行,缓存命中率不同
- 编译器/硬件优化,指令重排,影响多线程程序(对单线程基本安全)
多字操作不是原语(atomic)
*竞争条件
生产者和消费者并发,不同寄存器调用counter旧值
临界区(Critical Sections )
每个进程中访问共享数据资源的一段代码,称为临界区
当有进程正在执行自己的临界区代码(访问共享数据)时,其它进程不能执行临界区代码
避免竞态条件的要求:
1.没有两个进程可以同时在它们的关键区域内。(safety)
2.对于速度或cpu的数量,不做任何假设(即考虑速度和CPU数量为任何的情况)。
3.任何运行在其临界区之外的进程都不能阻塞其他进程。(可发展的-progress)
4.任何进程都不应该永远等待进入临界区域。(活性-liveness)

*忙等待互斥(Mutual Exclusion with Busy Waiting )
实现忙等待互斥的方法
在一个进程进入临界区时禁用中断(弊大于利,长时间禁用中断会产生很多麻烦)
设置锁-变量(Lock Variables ),进程进入临界区时把锁变量置为1,把集中在共享变量的问题转移到锁变量上而已
Strict Alternation,严格交替
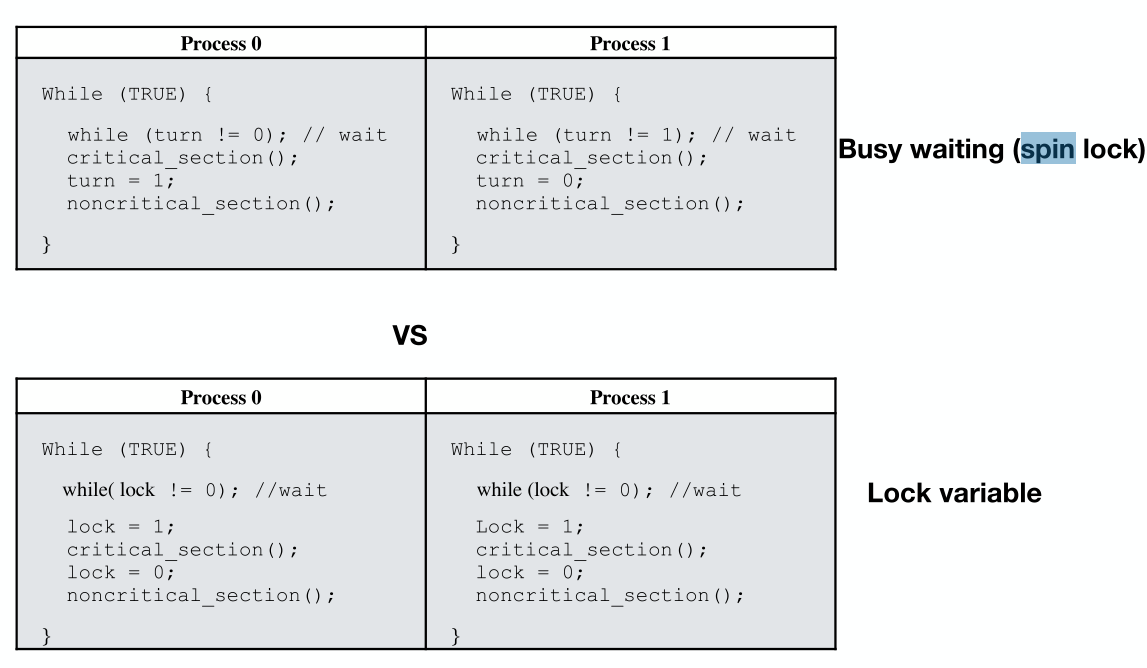 但是也存在问题:当一个进程执行特别快,在另一个进程仍在执行非临界区代码时,这个进程已经接过接力棒执行完自身临界区代码和非临界区代码,回到下一轮临界区入口前,它此时需要阻塞自己等待另一个进程执行完当前轮次和下一轮次(仅有两个进程时的讨论),这就违背了避免竞态条件第三原则——任何执行非临界区进程/线程不得阻塞其它进程/线程。
但是也存在问题:当一个进程执行特别快,在另一个进程仍在执行非临界区代码时,这个进程已经接过接力棒执行完自身临界区代码和非临界区代码,回到下一轮临界区入口前,它此时需要阻塞自己等待另一个进程执行完当前轮次和下一轮次(仅有两个进程时的讨论),这就违背了避免竞态条件第三原则——任何执行非临界区进程/线程不得阻塞其它进程/线程。Peterson’s Solution:皮特森方案,连接两个思想:严格交替和锁变量。
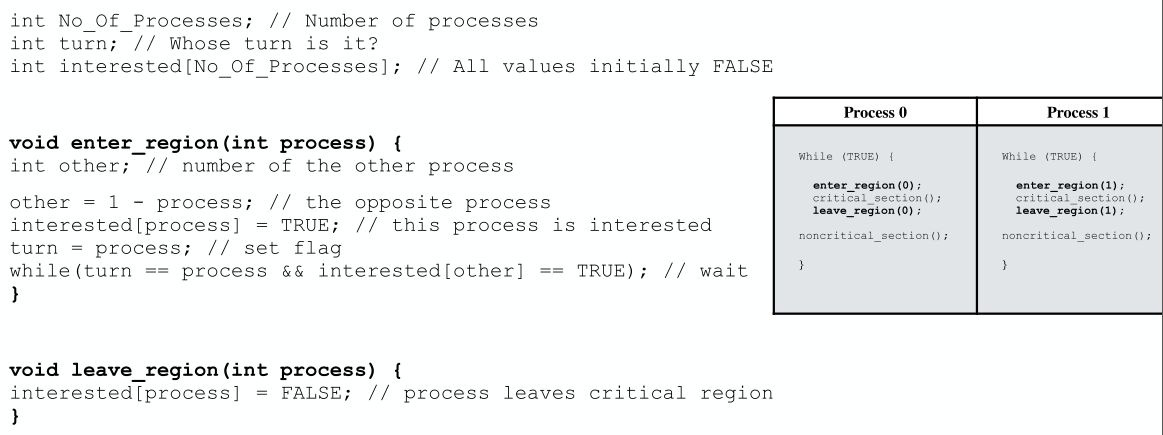
核心在于turn==process&&interested[other]==true时等待,前者保证多个进程并发时,最先改写turn值的进程会进入临界区,另一个会阻塞,后者保证进入非临界区时,interest会置为false,不会阻塞其它进程
扩展到N个线程互斥访问一个资源的filter算法[维基百科]
// initialization level[N] = { -1 }; // current level of processes 0...N-1 waiting[N-1] = { -1 }; // the waiting process of each level 0...N-2 // code for process #i for(l = 0; l < N-1; ++l) { // go through each level level[i] = l; waiting[l] = i; while(waiting[l] == i && (there exists k ≠ i, such that level[k] ≥ l)) { // busy wait } } // critical section level[i] = -1; // exit section数组level表示每个线程的等待级别,最小为0,最高为N-1,-1表示未设置。数组waiting模拟了一个阻塞(忙等待)的线程队列,从位置0为入队列,位置越大则入队列的时间越长。每个线程为了进入临界区,需要在队列的每个位置都经过一次,如果没有更高优先级的线程(考察数组level),cd 或者被后入队列的线程推着走(上述程序waiting[l] ≠ i),则当前线程在队列中向前走过一个位置。可见该算法满足互斥性。
由filter算法去反思Peterson算法,可见其中的flags(interested)数组表示两个进程的等待级别,而turn变量则是阻塞(忙等待)的线程队列,这个队列只需要容纳一个元素。
TSL指令:忙互斥的硬件实现
test and set lock (TSL),硬件层面对“test” and “set” the flag的原子性实现
这个指令读取一个内存地址的内容,存到寄存器中,并在原地址存一个非零值,保证指令过程中其它进程不能访问该内存地址
enter_region:
tsl register, flag ; copy flag to register and set flag to 1
cmp register, #0 ;was flag zero?
jnz enter_region ;if flag was non zero, lock was set , so loop
ret ;return (and enter critical region)
leave_region:
mov flag, #0 ; store zero in flag
ret ;returnx86中采用XCHG作为代替(原子地交换两个变量的值),作用基本一致
以上方法本质都是忙等待:进入临界区前检查,不符合条件循环忙等待。
会出现priority inversion problem(优先级反转)的问题。
解决方法:优先级继承协议,允许一个任务继承它正在阻塞的最高优先级任务的优先级
eg.
| Job Name | Priority |
|---|---|
| H | High |
| M | Medium |
| L | Low |
假定L获取到共享资源后,H申请该资源不得而被阻塞。优先级继承协议把L的优先级升级到H的级别。M将不能抢先L因而M被阻塞。当L释放资源后,恢复到低优先级并唤醒H。H有高优先级因而抢先了L的执行权。随后M、L依次恢复执行。
睡眠和唤醒
sleep, wakeup 不忙等待,不占用cpu
均含有参数——匹配sleep和wakeup的内存地址(指定进程)
生产者和消费者例子:
生产者向buffer增加item时(消费者减少item)检查buffer中的item count是不是等于n(0),如果是则sleep,否则正常操作;当从0到1(从n到n-1)时wakeup消费者(生产者)
int BUFFER_SIZE = 100;
int count = 0;
void producer(void) {
int item;
while(TRUE) {
produce_item(&item); // generate next item
if(count == BUFFER_SIZE) sleep (); // if buffer full, go to sleep
enter_item(item); // put item in buffer
count++; // increment count
if(count == 1) wakeup(consumer); // was buffer empty?
}
}
void consumer(void) {
int item;
while(TRUE) {
if(count == 0) sleep (); // if buffer is empty, sleep
remove_item(&item); // remove item from buffer
count--; // decrement count
if(count == BUFFER_SIZE - 1) wakeup(producer); // was buffer full?
consume_item(&item); // print item
}
}对于唯一的count,会产生类似的竞态条件问题
The Producer-Consumer Problem with spin lock protect,互斥锁的保护
mutex_lock:
TSL REGISTER,MUTEX ;| copy mutex to register and set mutex to 1
CMP REGISTER,#0 ;| was mutex zero?
JNE mutex_ lock ;| mutex is busy; loop
RET ;| return to caller; critical section entered
mutex_unlock:
MOVE MUTEX,#0 ;| store a 0 in mutex
RET ;| return to caller int BUFFER_SIZE = 100;
int count = 0;
int mutex = 0;
void producer(void) {
int item;
while(TRUE) {
produce_item(&item); // generate next item
mutex_lock(mutex);
if(count == BUFFER_SIZE) {
mutex_unlock(mutex);
sleep ();
mutex_lock(mutex);
} // if buffer full, go to sleep
enter_item(item); // put item in buffer
count++; // increment count
if(count == 1) wakeup(consumer); // was buffer empty?
mutex_unlock(mutex);
}
}
//...consumer略*条件变量
一个自动unlock和sleep的原语
一个同步对象,使线程有效地等待由锁保护的共享状态的更改
含有三种方法:
•Wait(ConditionVariable *cv, Lock * lock):自动释放锁(解锁),挂起调用线程的执行(sleep) -唤醒时重新获取锁
•Signal(ConditionVariable *cv):唤醒一个等待这个条件变量的等待者。如果等待列表中没有线程,则信号不起作用。
•Broadcast(ConditionVariable *cv):如果有,唤醒所有的等待者
int BUFFER_SIZE = 100;
int count = 0;
condition empty;
Condition full;
int mutex = 0;
void producer(void) {
int item;
while(TRUE) {
produce_item(&item); // generate next item
mutex_lock(mutex);
if(count == BUFFER_SIZE)
wait(full, mutex); // if buffer full, unlock, and go to sleep, when wakened -> lock
enter_item(item); // put item in buffer
count++; // increment count
if(count == 1) signal(empty); // was buffer empty?
mutex_unlock(mutex);
}
}
//...consumer略条件变量没有memory,如果一个信号被发送到一个没有线程等待的条件变量,这个信号就会丢失。
Linux中的实现:an FUTEX (Fast User-space muTEX) approach
//当且仅当地址addr的值等于val时,该操作使调用线程进入睡眠状态
#include <stdatomic.h>
#include <time.h>
#include <linux/futex.h>
int futex_wait(atomic_int *addr, int val)
{
return sys_futex(addr, val);
}
//该操作唤醒在地址addr的futex上等待的线程
int futex_wake(atomic_int *addr)
{
return sys_futex(addr);
}
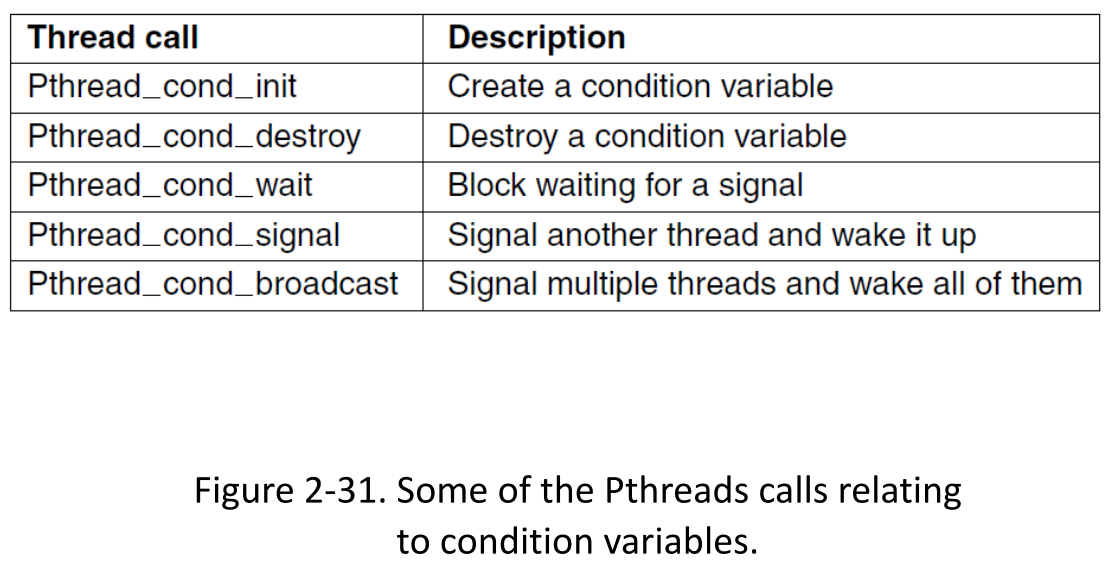
锁的规则-Rules for locks:
Lock is initially free
Always acquire before acces sing shared data structure
Beginning of procedure!
Always release after finishing with shared data
End of procedure!
Only the lock holder can release
DO NOT throw lock for someone else to release
Never access shared data without lock
Danger!
Rules for Condition Variables:
- ALWAYS hold lock when calling wait, signal, broadcast
- Condition variable is sync FOR shared state
- ALWAYS hold lock when accessing shared state
- Condition variable is memoryless
- If signal when no one is waiting, no operation
- If wait before signal, waiter wakes up
- Wait atomically releases lock
*信号量Semaphores
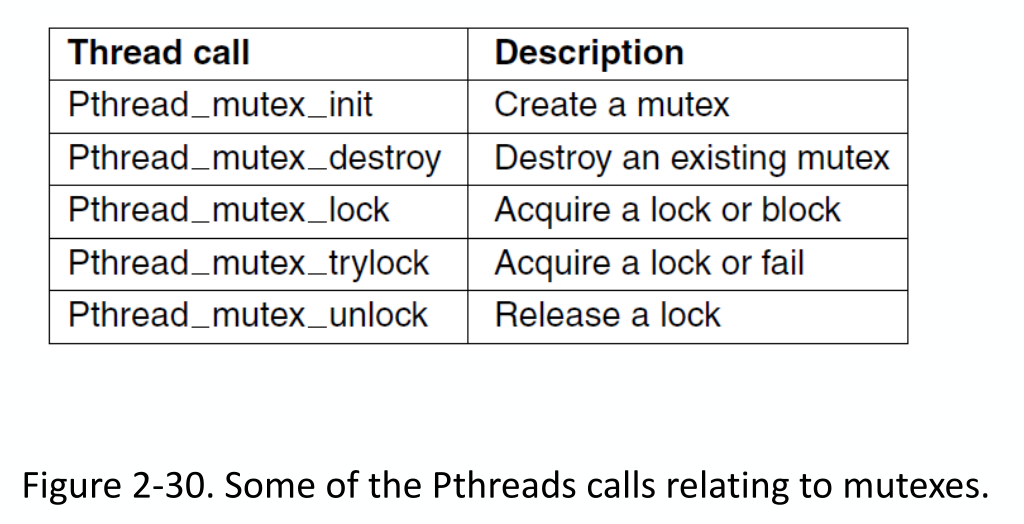
同步变量,一个整数值,无法通过外界访问,只能通过Semaphore操作:初始化,PV原语(P(), (or down() or wait()),检验,V() (or up() or signal()),自增;)
•如果信号量为正值,则将其视为跟踪有多少“资源”或“未激活的解除阻塞”可用
•如果信号量为负值,则跟踪有多少线程正在等待资源或解除阻塞
•提供排序和计数(“剩余”事件/资源)
P(检验操作)
//阻塞版本:递减s,如果结果小于0 则阻塞
P(s){
if (--s < 0)
block(s);
}
//自旋版本:等s增到正值开始递减
P(s){
while (s <= 0);
s--;
}V(自增操作)
//阻塞版本:递增s,如果结果小于等于0 则解除阻塞(代表此时无可用资源,有线程正在阻塞)
V(s){
if (++s <= 0)
unblock(s);
}
//自旋版本:等s增到正值开始递减
V(s){
s++
}生产者消费者版本
semaphore empty = N; //可以理解为等待线程队列?
semaphore full = 0;
int mutex = 0;
void producer(void) {
int item;
while(TRUE) {
produce_item(&item);
P(empty);
mutex_lock(mutex);
enter_item(item);
mutex_unlock(mutex);
V(full);
}
}
void consumer(void) {
int item;
while(TRUE) {
P(full);
mutex_lock(mutex);
remove_item(&item);
mutex_unlock(mutex);
V(empty);
consume_item(&item);
}
}使用了条件变量和互斥锁的信号量版本
#include<stdio.h>
#include<pthread.h>
typedef struct {
int val;
int mutex;
condition cond;
}semaphore;
void init(semaphore *s)
{
s->val = 0;
}
void P(semaphore *s)
{
mutex_lock(&(s->mutex));
if (s->val == 0) {
//wait(ConditionVariables *cv, Lock *lock)
wait(&(s->cond), &(s->mutex));
}
s->val--;
mutex_unlock(&(s->mutex));
}
void V(semaphore *s)
{
mutex_lock(&(s->mutex));
s->val++;
singal(&(s->cond));
mutex_unlock(&(s->mutex));
}互斥锁、条件变量和信号量之间的区别
互斥锁用于进入临界区
条件变量用于睡眠和唤醒,以避免繁忙等待。
条件变量应该通过互斥锁来使用
信号量是一种更高的抽象,由条件变量、互斥锁和计数数(表示资源的数量,count number)实现
信号量可用于I/O设备和等待I/O完成的线程之间的同步通信。
—通常,硬件通过共享内存数据结构与设备驱动程序通信。
—该数据结构由硬件和内核同时读写
如果硬件设备需要提示(attention),例如,因为一个需要处理的网络数据包已经到达,或者磁盘请求已经完成,硬件就会更新共享数据结构并启动中断处理程序。
—中断处理程序通常很简单:它只是唤醒一个等待的线程并返回。
一个常见的解决方案是设备中断使用信号量。对于每个设备,分配一个信号量,初始值为0。
线程(进程)调用P,等待(挂起)设备完成某事。
设备完成后,中断将调用V,然后线程将再次准备好
信号量的隐含危害
使用单独的锁和条件变量类使代码更具自文档性,更易于阅读。(既可以表示锁变量又可以表示条件变量的信号量可能不具有此优势)。
绑定到锁上的无状态条件变量比信号量(使用整数记录唤醒、休眠或资源的数量)是更好的广义等待抽象。
在使用信号量、锁、条件变量时,我们应该小心,因为简单的重新排序或缺少解锁都会导致非常糟糕的影响,导致程序行为的不正确。
Monitors
一个锁和零个或多个条件变量,用于管理对共享数据的并发访问
embedded in language:
•高级数据抽象,统一处理:共享数据,对它的操作,同步和调度
-数据结构上的所有操作都有一个(隐式)锁
-一个操作可以放弃控制并等待一个条件
•监视器是简单和安全的
-编译器可以检查,锁是隐式的(不能忘记)
•监视器有两种“等待”队列
-进入监视器:有一个线程队列等待获得互斥和进入
-条件变量:每个条件变量有一个线程队列等待相关的条件
…
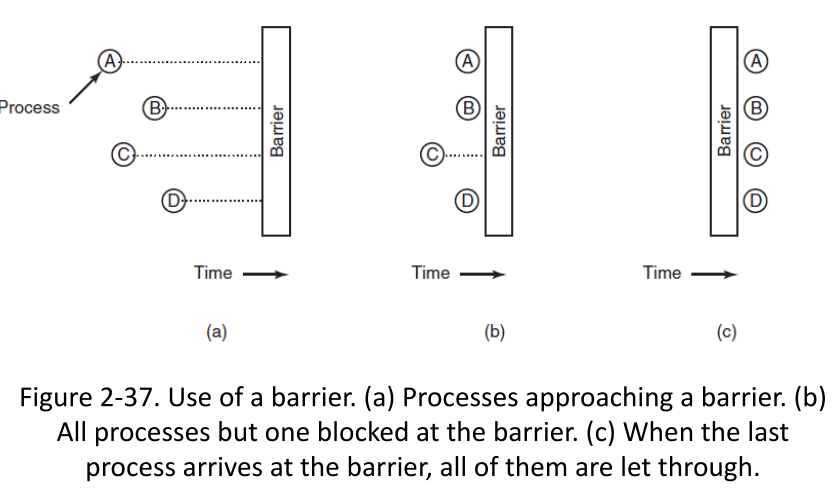
Barriers
等待所有进程/线程都到达计算点(at point in computation)后再继续
separate phases of a multi-phase algorithm (多阶段算法的分离阶段)
二元性和互斥:包括其余所有而非排除其余所有
…
案例
作家读者问题
特点
允许多个线程同时read数据
同一时间仅能有一个writer写数据
writer写数据时不能有reader
读写锁(RWLock)用来保护共享数据,实现了任意writer间的互斥和任意writer和reader间的互斥
…
Avoiding Locks: Read-Copy-Update
reader应当可以选择查看旧值或writer实时更新的新值
RCU:reader与writer并发运,不显式地与writer同步
三大基本机制:发布-订阅机制,等待已存在的reader完成,维护最近更新对象的多个版本
…
宽限期:等reader读取完数据再删除(覆盖)旧数据
实现
•Readers disable interrupts on entry –Guarantees they complete critical section in a timely fashion –No read or write lock •Writer –Acquire write lock –Compute new data structure –Publish new version with atomic instruction –Release write lock –Wait for Ume slice on each CPU –Only then, garbage collect old version of data structureRCU的局限:
它适用于Publish-Subscribe更新模式,当数据比较复杂时(比如双链表,需要同时更新两个指针),使用RCU可能比较困难。
宽限期(grace period)可能太长(RCU提供了一个异步回调函数call_rcu())
哲学家就餐问题
圆桌,五个哲学家就坐,五盘意大利面,五个叉子放在间隙,每个哲学家需要两个叉子就餐
每个哲学家会进行以下循环:
– Think for a while
– Get 2 forks
– Eat for a while
– Put down the forks
– Repeat
设计Get 2 forks的方案
deadlock和starvation,死锁一定饿死,饿死不一定是死锁,死锁条件更强 。在饥饿状态下,线程在一段不确定的时间内无法取得进展。死锁是饥饿的一种形式,但条件更强:一组线程形成一个循环,其中没有一个线程取得进展,因为每个线程都在等待循环中的其他线程采取行动。
随即回退值
哲学家应当能互相沟通,当邻居哲学家正在吃时不应该拿叉子,沟通饿的意愿
#define N 5 /* number of philosophers */
#define LEFT (i−1+N)%N /* number of i’s left neighbor */
#define RIGHT (i+1)%N /* number of i’s right neighbor */
#define THINKING 0 /* philosopher is thinking */
#define HUNGRY 1 /* philosopher is trying to get forks */
#define EATING 2 /* philosopher is eating */
int state[N]; /* array to keep track of everyone’s state */
semaphore mutex = 1; /* mutual exclusion for critical regions */
semaphore s[N]; /* one semaphore per philosopher */
void philosopher(int i) {
while (TRUE) {
think();
take_forks(i);
eat();
put_forks(i);
}
}
void take_forks(i){ /* i: philosopher number, from 0 to N−1 */
mutex.P(); /* enter critical region */
state[i] = HUNGRY; /* record that philosopher i is hungry */
test(i); /* try to acquire 2 forks */
mutex.V(); /* exit critical region */
s[i].P(); /* block if forks were not acquired */
}
void put_forks(i){ /* i: philosopher number, from 0 to N−1 */
mutex.P(); /* enter critical region */
state[i] = THINKING; /* philosopher has finished eating */
test(LEFT); /* see if left neighbor can now eat */
test(RIGHT); /* see if right neighbor can now eat */
mutex.V(); /* exit critical region */
}
void test(i) /* i: philosopher number, from 0 to N−1 */
{
if (state[i] == HUNGRY && state[LEFT] != EATING &&state[RIGHT] != EATING) {
state[i] = EATING;
s[i].V();
}
} 死锁
资源
可抢占资源和不可抢占资源,前者可从占有进程控制中直接夺走,而不会造成不良影响,后者反之
死锁通常涉及不可抢占资源,涉及可抢占资源的死锁通常可由重新将进程资源分配给另一个进程解决(因为资源可抢占)。
*死锁介绍
一个集合的进程是死锁当且仅当:
- 集合中每个进程均在等待某个事件(每个进程等待事件不必相同)
- 这个事件仅能被除当前阻塞进程外的进程触发
死锁的四个必要条件(并非充要条件)
互斥(Mutual exclusion):同一时间内,同一资源只能被一个进程使用。(或者有限个进程可以同时使用同一资源,但也可以理解为存在相同的多个资源)
持有并等待(Hold and wait):一个持有至少一个资源的进程正在等待获得其他进程持有的额外资源。
不可抢占(No preemption):进程所占资源仅能完成任务后自愿释放
环路等待(Circular wait condition):存在一个集合{P0, P1,…,Pn},其中n > 1,P0等待P1持有的一个(或多个)资源,P1等待P2持有的一个(或多个)资源,…,Pn - 1等待Pn持有的一个(或多个)资源,Pn等待P0持有的一个(或多个)资源
特殊情况:单进程也可能死锁——递归,此时可改锁为整数,锁自己时递增,解锁递减,为0时才真解锁
// Thread A
function callA(){
lock.acquire();
callA();
lock.release();
}
callA();建模
Resource-Allocation Graph资源分配图
—圆:表示进程。
—正方形:资源。
—从资源节点(方形)到流程节点(圆形)的有向弧线表示该资源目前由该流程持有。
—从进程节点到资源节点的有向弧线表示进程当前正在阻塞等待该资源。
画有向图,有环则有死锁(同一类型资源有多个时则不一定)
鸵鸟算法-死锁解决办法
The ostrich algorithm ,忽略问题也许问题就会消失
—用于大多数操作系统,包括UNIX
•检测和恢复。让死锁发生,检测死锁并采取行动。
•确保系统永远不会进入死锁状态
-通过仔细分配资源来动态避免。
-预防,从结构上否定四个必要条件之一。
鸵鸟算法广泛使用在于死锁的危害和修复死锁所需要付出的代价之间的平衡。
*死锁检测和恢复
每种类型一个资源->可以利用环路检测算法进行死锁检测
深度优先搜索
1.对于图中的每个节点(N),以N为起始节点执行以下5步。
- 初始化L为空列表,并指定所有弧为未标记。
- 将当前节点添加到L的末端,检查节点现在是否出现在L中两次。如果是,则图包含一个循环(列在L中),算法终止
- 从给定的节点,看看是否有任何未标记的输出弧线。如果是,请转步骤5;如果没有,请转步骤6。
- 随机选取未标记的出弧,标记出来。然后按照新的当前节点,转到步骤3。
- 如果这是初始节点,则图中不包含循环,算法终止。否则,含有死锁。删除它并返回到前一个节点
但是不够优秀,存在很多冗余步骤,理论上复杂度为O(E+V),所有顶点和边均遍历一遍即可。
每种类型一个资源每种类型多个资源->环路检测算法失效,需要利用基于资源分配矩阵、请求矩阵、可用向量的算法进行检测
…没看
恢复:抢占(Preemption),回滚(Rollback),杀死进程
- preemption:把资源抢走分配给另一个,原进程挂起,执行结束后再唤醒
- rollback:设置检查点,存储进程状态(内存映像和资源状态,新旧检查点不能覆盖),回滚到占用资源之前的状态
- 终止所有涉及死锁的进程,可以一次解决或者每次终止一个(按进程优先级、进程运行时间、资源使用情况、待完成情况)
*死锁避免(Deadlock Avoidance)
通过合理分配资源来避免死锁(过去,进程一次请求全部资源,如今每次请求一个或几个资源)
资源轨迹(resource trajectories)
安全状态(safe)、非安全状态(Unsafe)
现有资源向量E,可用资源向量A,当前分配矩阵C,最大请求矩阵M,请求向量R

…
银行家算法(Banker’s algorithm)
检查是否允许请求导致不安全状态。
如果是,则拒绝请求。如果授予请求导致安全状态,则执行请求。
剩余需求矩阵N,N[i][j] = M[i][j]−C[i][j]
安全检查算法应:
1.尝试最坏的情况:让每个进程请求它们所需的最大资源。
2.调用死锁检测算法,如果它导致死锁,那么它是不安全的。
3.否则,它是安全的。
具体操作:
\1. 寻找一行N,其未满足的资源需求都小于或等于A。如果不存在这样的行,系统将最终死锁。
\2. 假设所选行的进程请求所需的所有资源并结束。将该进程标记为终止,将其资源添加到A向量。
3.重复步骤1和2,直到所有进程都标记为终止(安全状态),或者没有可以满足资源需求的进程(死锁)。
防止死锁
确保至少有一个条件从未被满足–互斥(Mutual exclusion)、持有并等待(Hold and wait)、不可抢占(No preemption)、环路等待(Circular wait condition)
…
其他问题
…
摘要
…
内存管理
内存管理的功能
•当有多个进程正在使用内存和资源时,在主存中处理所有与内存相关的操作和资源
—跟踪内存的哪些部分正在使用
—在需要时为进程分配内存,并在它们完成时释放内存
—保护所需的内存以确保正确的操作
—扩展物理内存的限制
•最大化内存利用率和系统吞吐量
• Control & Efficiency 控制与效率
虚拟和物理地址空间
虚地址转换,MMU(Memory-Management Unit ),内存粒度
*进程级、分段和分页
地址转换
在物理内存中连续地分配地址空间
Base和Limit (Bound):使用两个特殊的硬件寄存器来定义地址空间(动态重定位-dynamic relocation)•Base:进程在内存中开始的物理地址•Limit:内存区域的长度
非常简陋,保护几乎没有(粗粒度),不能增加堆栈,不能和其他进程共享代码
*分页
–页表和页表项
–页面共享
–写时复制 (Copy on Write)
–转换检测缓冲区/快表 (TLB) 和 TLB Miss
–有效访问时间
–多级页表
–页面大小

*虚拟内存
缺页错误 (Page Fault) 及其处理流程
处理页面错误的三个主要活动:•服务中断:仔细编码意味着只需要几百条指令•读取页面:大量时间•重新启动进程:少量时间
页面置换算法:
FIFO:替换最老的
Optimal:替换长时间不使用的页面
Least Recently Used (LRU):替换在大多数时间内未被使用的页面(需要计数器来统计)
Approximating LRU (Second Chane, NRU, Aging):
second chance
•当一个页面被引用(即读或写)时,引用位被设置为1(由硬件)
•如果要替换的页面有
•R = 1(最近使用):设置R位为0;
•R = 0:替换它
•如果所有页面都被引用,第二次机会= FIFO
NRU:通过引用位+修改位(最近未使用,NRU)近似LRU:为那些修改的页面分配更高的优先级,以减少I/O(增强的第二次机会)
aging:老化算法
通过额外的参考位:保持一个软件计数器来跟踪每个页面被引用的频率,并用最小的计数替换页面
•每个页面对应一个软件计数器
•在每次时钟中断时
—计数器每个右移1位
—R位增加到最左边
•数值越大表示最近使用的页面
—选择01110111页面替换,而不是11000100页面
• Demand Paging: bring a page into memory only when it is
needed
• Prefetching: guess which pages are about to be used, and thus bring it in ahead of time
工作集模型
–抖动 (Thrashing)
如果一个进程没有“足够”的页面,页面故障率就会非常高。此时,应降低多路编程的程度,作为换出进程可以释放其帧。
Thrashing:进程将所有时间用于交换页面(大多数引用会导致页面错误)
–访问局部性 (Principle of Locality)
时间、空间
工作集
•工作集:页面的集合过程中使用最近的k内存引用——如果整个工作集是在内存中,这一过程会不会引起许多缺点,直到它进入另一个执行阶段,如果可用内存太小,不能容纳整个工作集,抖动发生•跟踪每个进程的工作集,并确保它在内存之前让进程运行,大大降低故障率的页面
页框的全局和局部分配策略
需求分页
页面替换
页面缓冲
帧分配
内存分配
*连续内存分配
当一个程序开始运行时,操作系统决定它应该在物理内存的哪里被加载,并设置base寄存器和limit寄存器(在内存中为它的地址空间寻找空间)•当在进程之间切换时,操作系统必须保存和恢复base-and-limit pair•当用户程序试图非法访问内存(可能会终止进程)时,操作系统必须提供异常处理程序
空闲空间管理
动态空间分配算法
First-Fit:第一次分配足够大的hole,目的是尽可能减少搜索次数
Next-Fit:跟踪上一次分配的hole,并在上次停止的位置开始第一次匹配的搜索,性能比first-fit略差
Best-Fit:分配最小的足够大的hole,需要search整个list,可能产生小而无用的hole从而产生浪费
Worst-Fit:分配最大的洞——也搜索整个列表——也不是一个很好的主意
Quick-Fit:一些更常见的请求大小维护单独的列表-找到所需大小的hole非常快-但hole应该按大小排序(当进程终止时)
内部碎片和外部碎片
地址保护
内存扩展
文件系统
*文件系统的功能
为应用程序提供持久的和命名的数据
•长期信息存储的基本要求-存储非常大量的信息-当进程终止时信息必须存活-多个进程必须能够同时访问信息
文件系统—为存储提供用户界面,将逻辑块映射到物理—通过允许数据存储、定位和轻松检索来高效访问磁盘
核心功能
•持久命名数据:文件和目录-存储直到它被显式删除,即使存储它的计算机崩溃或断电-可以通过文件系统与文件关联的人类可读标识符访问
•访问和保护:提供打开,读,写和其他操作;协调不同用户对文件的访问
•磁盘管理:公平高效地使用磁盘空间—为文件分配空间并跟踪空闲空间—快速访问文件
•可靠性:不能丢失文件数据
*文件
可以创建,读取,写入和删除的字节(由用户定义的类型)的线性数组,一种抽象机制,提供了一种将信息存储在磁盘上并稍后读取的方法
命名
人类可读命名,扩展名
属性
类型:常规文件:包含用户信息的文件(ASCII文件:由文本行组成;二进制文件:具有特定程序所知道的一些内部结构);目录文件:用于维护文件系统结构的系统文件;特殊文件:字符(打印机),块(磁带),……•每个操作系统都必须至少识别一种文件类型:它自己的可执行文件
metadata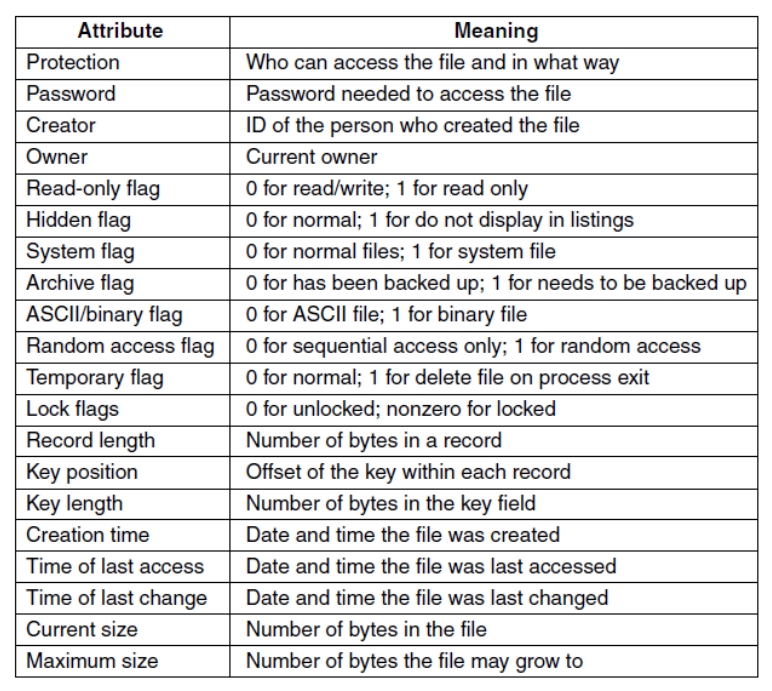
文件系统应该将文件元数据保存在一个结构中:索引节点(inode) (UNIX中给出的历史名称),驻留在磁盘上,缓存在内存中以加快访问速度
文件访问
顺序访问
read next / write next / reset,最常见,比如复制文件、编译器读取和写入,可以非常快
随机访问模式
read n / write n / seek n,包含块数作为参数,不快
与文件相关的操作
存储和检索信息的操作
•Create:宣布文件并设置属性•Delete:释放磁盘空间•Open:将属性和磁盘地址列表提取到主存中进行快速访问•Close:释放内部表空间,强制写入文件的最后一个块•Read:从文件中读取数据(指定需要多少数据并提供缓冲区)•Write:将数据写入文件(在当前位置)•Append:限制写操作的形式•Seek:在文件中重新定位(指定从哪里获取数据)•Get and Set Attributes:读取和更改文件属性•Rename:更改文件名称
•一些系统只提供了文件操作的最小系统调用集(其他操作可以使用这些操作实现)
文件描述符 (File Descriptor)
由操作系统分配的用于引用文件的唯一编号(每个进程私有)
•避免解析文件名(在目录中搜索文件名)并检查每次访问的权限
•执行某些操作的能力

打开文件表 (Open-File Table)
进程打开文件时,OS要创建一个存储文件信息的数据结构
每个进程维护一个打开文件表(由文件描述符索引的数组),表中的每个条目都跟踪文件描述符引用的底层文件、当前偏移量和其他相关详细信息(例如权限)
per-process open-file table:跟踪所有被进程打开的文件
system-wide open-file table:跟踪与进程无关的信息,系统维护所有打开文件的信息
打开文件步骤:在系统打开文件表中寻找这个文件条目(如果没有则在目录中寻找文件名,找到后添加到系统打开文件表中);在每进程文件打开表中创建一个指向系统打开文件表对应条目的条目;自增系统打开文件表的open count(仅有当此变量为0时才能移除对应条目);返回一个指向每进程文件打开表中对应条目的指针
三个描述文件描述符和打开文件关系的表(Unix中):
•文件描述符表(每个进程的):每个由进程打开的文件描述符都有一个条目——引用打开文件描述
•打开文件表(系统):每个打开的文件都有一个条目——文件偏移量,访问模式,状态标志——参考inode对象文件
•inode表(系统):每个索引节点都有一个条目,文件类型权限,其他属性(大小、时间戳、…
偏移 (Offset)
对于进程打开的每个文件,操作系统都会跟踪文件偏移量,这决定了下一次读或写将从哪里开始
•隐式更新(当发生N个字节的读或写时,N被添加到当前偏移量)
•通过系统调用显式更新:lseek()
*目录
目录操作
目录的层级结构(在目录中放置目录)
目录存储人类可读文件名和低级文件索引(inode号)之间的映射
⟨文件名,文件索引⟩pair的表
为根目录分配固定的inode号
从文件路径名到文件 inode 的转换
根目录中寻找对应inode,找到对应磁盘block,到磁盘再找inode…
硬链接 (Hard Link) 和符号链接 (Symbolic Link)
新文件链接到旧文件名,同一文件有了多个名字,目录结构是有向无环图
硬链接依赖inode,每个inode对应一个独一无二的文件,对inode的引用,系统有计数,计数减到0文件就算被删除。unlink()可以减少计数;存在规则:不能跨文件系统链接(inode仅在同一文件系统内唯一),不能链接到目录(防止出现环);文件所有者仅有一个。
软链接依赖路径名:生产一个存储了链接文件路径的link类型文件;可以跨文件系统,可以递归链接(链接目录、甚至link类型文件)
文件系统挂载(Mount)
*文件系统的布局
Superblock, bitmap, inodes, data blocks
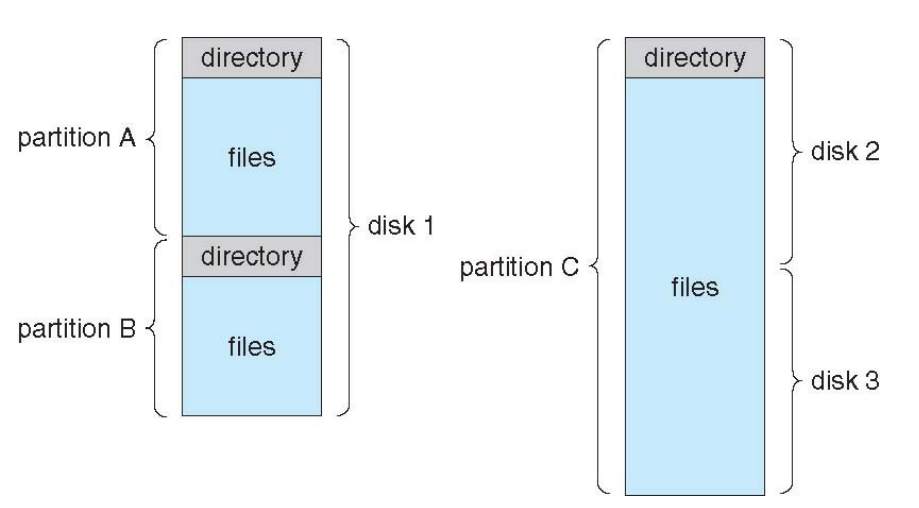
单个物理磁盘可以划分并存储多个卷,也可以将多个物理磁盘组合在一起,使单个卷跨越多个物理磁盘,包含文件系统的分区称为卷
文件系统维护数据存储的磁盘结构,磁盘分块block:数据区域,inode表区域(文件的metadata),分配结构(存储磁盘已分配信息和空余信息,data region和inode table各一个),superblock(存储文件系统信息,文件系统类型,inode数量,block数量,inode table起始位置,是挂载文件系统时第一个被读取的block)

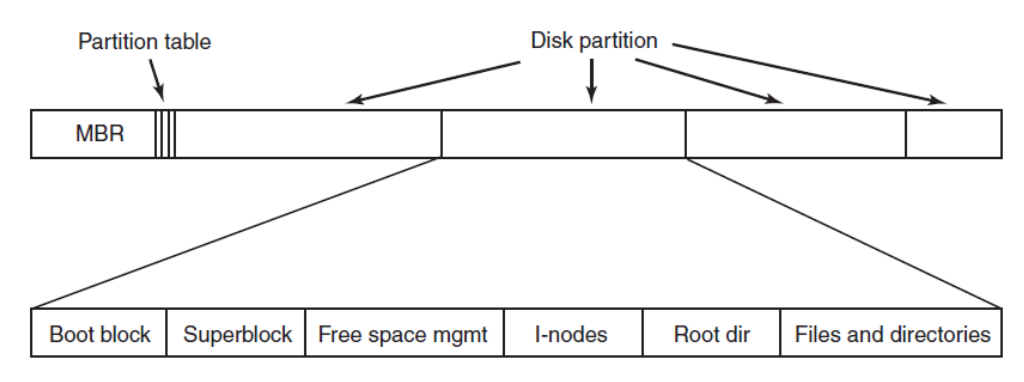
引导块(boot block):引导OS所需的信息,通常是分区的第一个块(如果没有OS则为空)
主引导记录(MBR):引导计算机的信息
分区表(Partition Table):每个分区的开始和结束地址(其中一个标记为活动)
文件系统还需要维护用于数据访问的内存结构(反映和扩展磁盘结构)•挂载表:关于文件系统挂载的信息(挂载点,文件系统类型)•开放文件表:全系统级和每进程级•目录结构:关于最近访问的目录的信息•I/O内存缓冲区:当文件系统块被读取或写入磁盘时保存它们
*文件的组织
文件需要分配磁盘块来存储数据,并具有指向数据块所在位置的结构
Contiguous
连续分配,每个文件占用一组连续的块
•只需要第一个块的磁盘地址和块的个数。•可以高效地实现顺序访问。•也可以快速计算任意地址的数据位置
不灵活,文件创建时就需要指定文件大小,容易产生磁盘碎片。适合DVD和CD-ROM;有的文件系统用extend-based,比block更大,是连续block形成的extend(区段)
Linked List
a linked list of blocks,每个block含有指向next的指针
没有外部碎片,也只需要第一个block的地址
缺点在于随机访问慢,指针浪费空间,可靠性不高
可以采用cluster of blocks改进,但内部可能产生碎片
File Allocation Table
链表分配的变种,用于MS-DOS,把所有指针放进FAT
每个FAT条目对应一个磁盘block,每个条目包含一个指向代表了相同文件的block的FAT条目的指针,或者文件末尾值
目录同样可以存储起始块号,提供随机访问(在内存中搜索FAT),用两个这样的表备份
缺点在与内存开销大(FAT表必须一直在内存中)
Indexed (inode 的多级索引设计)
每个文件都有一个指向块的指针数组(索引block)
索引块只在相应文件打开时才需要在内存中,大小只跟一次需要打开的最大文件block大小有关(还是可能很大)
多级索引:可以有间接指针块(不是指向包含用户数据的块,而是指向包含更多指针的块),针对更大文件可以有多重指针块,不平衡树
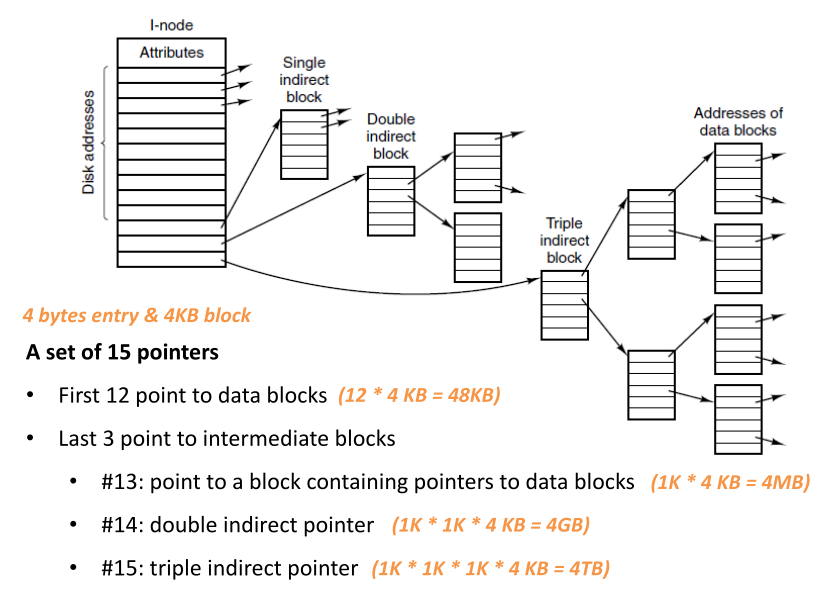
文件碎片-大多数文件都很小(平均200kB)
最佳的文件组织方法取决于-文件系统的特征-文件访问类型(例如,连续的适合顺序)-…
考虑要素:快速查找数据进行顺序和/或随机访问-内部和外部碎片-易于实现-支持文件增长-存储开销
*目录的组织
–目录项中包含的信息、不同长度文件名的处理
⟨file name, file index⟩ mapping
包含的信息可能为:—整个文件的磁盘地址—第一个块号—inode号
文件属性(metadata)可以直接存储在目录条目中(固定大小的条目大小),或者每个目录条目只引用一个inode(只有文件名+ inode号)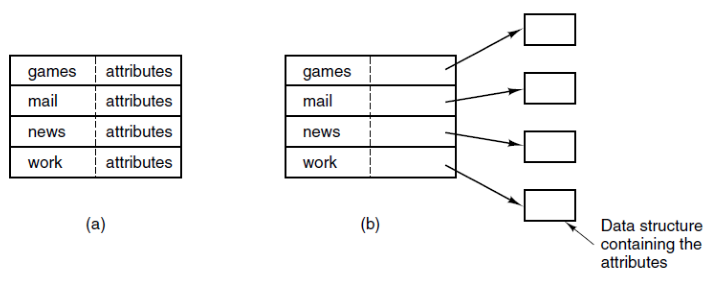
两种组织方法:
entry长度不一致:条目长度(固定)—属性(固定)—文件名(以特殊字符结束)•当一个文件被删除时,会引入一个可变大小的间隙
一致:保持所有的文件名在一个堆中•当一个条目被删除,下一个输入的文件将始终适合•文件名不需要从单词边界开始•必须管理堆
*文件系统的性能
如何跟踪哪些索引节点和数据块是空闲的?•当一个新的文件或目录被分配时,文件系统可以为它找到空间;位图bitmap和自由列表free list是两种常见的方法•更复杂的数据结构,如b -树也被使用
bitmap:每一位代表一个block的状态,能比较容易地找到连续磁盘空间,需要额外空间存储位图
free list:把空闲空间串成一个链表,让每个块拥有尽可能多的空闲磁盘块号(分组)-对于1KB的块,和4字节的块号,每个块拥有255个空闲块-分配多个空闲块不需要遍历列表;不浪费空间,寻找和分配(需要遍历)比较麻烦;部分block装满,部分不装满(解决频繁I/O造成的性能浪费)
读文件的步骤:
•首先,打开文件-遍历路径名并找到所需的inode -读取该inode,执行权限检查,返回文件描述符
•然后,对于发出的每个读操作-读取inode -读取数据块-写入inode(更新上次访问时间) -在打开的文件表(内存)中更新文件偏移量
缓存 (Cache and Buffering)
将经常使用的块保留在内存中:如果需要的块在内存中,则不需要I/O就读取它•使用哈希表跟踪给定的块是否存在•当缓存满时必须删除一些块(类似于页面替换问题);提前读取常用block到内存;写延迟,优化写操作(回写和直写);
快速文件系统 (FFS)
disk-awareness的文件系统
通过在同一个组中放置两个文件,FFS确保访问一个文件后不会导致长时间的磁盘查找
实现数据局部性原则
对于文件-将数据块分配到与其inode相同的组中-将同一目录下的所有文件放在它们所在的目录组中
对于目录-找到已分配目录数量较少(以平衡组间的目录)和空闲inode数量较多(以能够分配一堆文件)的组-将目录数据和inode放在该组中
*文件系统的一致性
•对文件系统的更新操作需要多次I/O操作(更新多个数据结构)—崩溃时,一些操作可能完成,一些操作可能丢失•使文件系统处于不一致状态
写操作步骤:•在文件中追加一个数据块—写入新的数据块—写入文件的inode—写入数据位图
后两步骤出现崩溃会出现一致性问题
文件系统一致性检查 (fsck)
File System Consistency Check,在挂载文件系统之前运行(假设在运行时没有文件系统活动),并确保文件系统元数据在内部保持一致
• Sanity check the superblock
• Check validity of free block and bitmaps
• Check that inodes are not corrupted
• Check inode links
• Check for duplicate pointers and bad blocks
• Check directories•检查超级块•检查空闲块和位图的有效性•检查inode是否损坏•检查inode链接•检查重复的指针和坏块•检查目录
太慢,对文件系统知识要求高
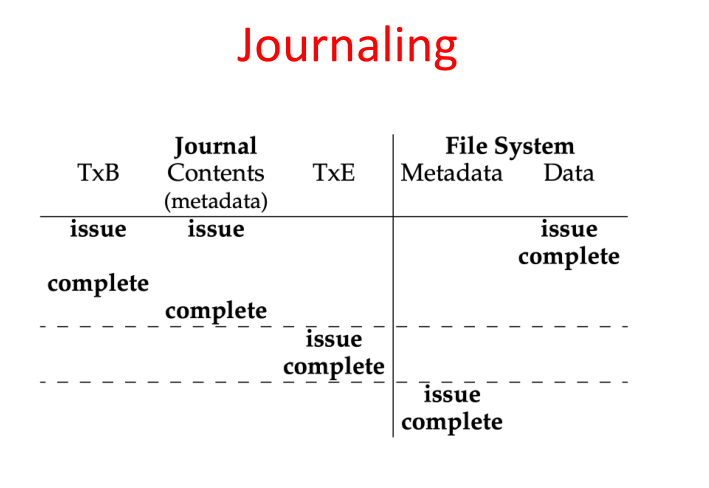
日志文件系统 (Journaling)
write-ahead logging,覆写结构之前,记录即将进行的操作
循环日志,日志大小固定,花费高
元数据日志
*虚拟文件系统
设备管理
• Input/Output (I/O) devices
– How should I/O be integrated into systems?
– What are the general mechanisms?
• Hard disk drive
– How is the data actually laid out and accessed?
– How does disk scheduling improve performance?
• RAID
– How can we make a large, fast, and reliable storage system?
*I/O 设备的交互
Polling, Interrupts, DMA
*磁盘
–寻道时间和旋转延迟
–磁盘调度算法: First Come First Service (FCFS), Shortest Seek First (SSF), Elevator (SCAN)
SSF:按轨道排列I/O请求队列,选择最近轨道上的请求先完成,可能造成饿死
SCAN:简单地在磁盘服务请求上按顺序在磁道上来回移动(就像电梯一样)•一次通过磁盘(从外磁道到内磁道,或从内磁道到外磁道)称为扫描
汇编文件相关
至少三个节
.data
程序已初始化的数据,具有初值的变量
.text
包含程序代码,只读节
.bss
包含未初始化变量,不占用空间,操作系统装入时全置为0
常用指令
.ascii
.ascii “string” …ascii 表示零个或多个(用逗号隔开)字符串,并把每个字符串(结尾不自动加“\0”字符)中的字符放在连续的地址单元。
与此类似的 .asciz指令定义的字符串会在结尾处自动加 “\0”字符
.fill
.fill repeat [, size , value]反复拷贝size个字节,重复repeat次 ,其中size和value是可选的,默认值分别为1和0
.global
.global symbol使得链接程序(ld)能识别symbol,局部程序中定义了.global symbol,则在与其链接的其它局部程序中也能存取symbol
内联汇编
使用内嵌汇编,要先编写汇编指令模板,然后将C语言表达式与指令的操作数相关联,并告诉GCC对这些操作有哪些限制条件。例如下面的汇编语句:
__asm__ __violate__ ("movl %1,%0" : "=r" (result) : "r" (input));
“movl %1,%0”是指令模板;“%0”和“%1”代表指令的操作数,称为占位符,“=r”代表它之后是输入变量且需用到寄存器,指令模板后面用小括号括起来的是C语言表达式 ,其中input是输入变量,该指令会完成把input的值复制到result中的操作
内嵌汇编语法如下:
__asm__(
汇编语句模板:
输出部分:
输入部分:
破坏描述部分);
即格式为asm ( "statements" : output_regs : input_regs : clobbered_regs)汇编语法相关
环境语法
旧版本的GAS把”.code16”解释为“生成32位指令,但是隐式地插入addr32(Address-Size Prefix 67H)和data32(Operand-Size Prefix 66H)指令来使代码工作在实模式下”。
新版本的GAS把”.code16”解释为“生成看似正确的16位指令”。这要求,当程序员想要使用32位得地址或是数据时,自己显示地插入addr32和data32指令。
data32 addr32 lgdt gdtDesc # loading gdtr, data32, addr32
...
data32 ljmp $0x08, $start32 # reload code segment selector and ljmp to start32, data32条件跳转和其它指令配合
Intel格式
无符号数比较
基于无符号数比较的跳转如下表所示。操作数的名称反映了表达式中操作数的顺序(比如 leftOp < rightOp)。下表中的跳转仅在比较无符号数值时才有意义。有符号操作数使用不同的跳转指令。
| 助记符 | 说明 | 助记符 | 说明 |
|---|---|---|---|
| JA | 大于跳转(若 leftOp > rightOp) | JB | 小于跳转(若 leftOp < rightOp) |
| JNBE | 不小于或等于跳转(与 JA 相同) | JNAE | 不大于或等于跳转(与 JB 相同) |
| JAE | 大于或等于跳转(若 leftOp ≥ rightOp) | JBE | 小于或等于跳转(若 leftOp ≤ rightOp) |
| JNB | 不小于跳转(与 JAE 相同) | JNA | 不大于跳转(与 JBE 相同) |
有符号数比较
下表列岀了基于有符号数比较的跳转。下面的指令序列展示了两个有符号数值的比较:
| 助记符 | 说明 | 助记符 | 说明 |
|---|---|---|---|
| JG | 大于跳转(若 leftOp > rightOp) | JL | 小于跳转(若 leftOp < rightOp) |
| JNLE | 不小于或等于跳转(与 JG 相同) | JNGE | 不大于或等于跳转(与 JL 相同) |
| JGE | 大于或等于跳转(若 leftOp ≥ rightOp) | JLE | 小于或等于跳转(若 leftOp ≤ rightOp) |
| JNL | 不小于跳转(与 JGE 相同) | JNG | 不大于跳转(与 JLE 相同) |
mov al, +127 ;十六进制数值 7Fh
cmp al, -128 ;十六进制数值 80h
ja Is Above ;不跳转,因为 7Fh < 80h
jg IsGreater ;跳转,因为 +127 > -128
由于无符号数 7Fh 小于无符号数 80h,因此,为无符号数比较而设计的 JA 指令不发生跳转。另一方面,由于 +127 大于 -128,因此,为有符号数比较而设计的 JG 指令发生跳转。
AT&T格式中则是比较rightOp operator leftOp
iret
iret 指令描述为:pop IP pop CS popf
iret指令执行后,CPU回到执行中断处理程序前的执行点继续执行程序
old_CS = CS
pop EIP
pop CS
pop EFLAGS
if(GDT[old_CS].DPL < GDT[CS].DPL)
pop ESP
pop SSjmp指令
假如标签叫做mylabel,它的地址是0x8048377,而且有个全局变量b,b存储的内容就是mylabel的地址,而b的地址是0x80494A8。
即有这样的赋值(加载)语句:
movl $mylabel,%eax //把mylabel的地址加载到eax寄存器中
movl %eax,b //把mylabel的地址加载到b中
movl $b,%ebx //把b的地址加载到ebx寄存器中
我们考虑下面的语句:
1.jmp mylable
2.jmp 0x8048377
3.jmp %eax
4.jmp *%eax
5.jmp *(%ebx)
6.jmp *0x80494A8
7.jmp *b
8.jmp $0x5
这8句jmp语句!分别都做了什么?
1.不用说,跳转到mylabel标签处继续执行代码,但是,是如何跳转的呢?就是PC加上了mylabel标签处对于jmp处的一个偏移地址!可执行的二进制代码是这样表示的:eb 03,就是说,pc+0x03就可以了。
2.这里,0x8048377是mylabel的地址,我以前研究过,标签的作用,更他的地址的作用是等效的。所以,这里的执行效果跟1中的相同。但是,还有些不一样!这里的二进制代码成了:e9 03 00 00 00 这里用了32位表示了这个偏移,而在1中,只用了8位!
3.在编译链接的时候,这句代码会有警告:warning:indirect jmp without ‘*‘。间接跳转没有‘*’符号,但是,执行起来,还是没有错。看一下二进制的可执行文件的代码,发现,给补上了个‘*’号!而且二进制是:ff e0.
4.其实,4是3的补充版,正常的形式就是4,而三是有警告的被补充的版本。
5.%ebx是b的地址,那么(%ebx)表示ebx的值为地址,指向的地方。这里指向了b的内容,也就是mylabel的地址!于是,化简后,5也就等效与2,但是,二进制表示是:ff 23。
6.0x80494A8是b的地址,这里看做内存数,那么实质上,b指向的值是mylabel的地址,于是,化简后同2,二进制代码是:ff 25 a8 94 04 08。
7.b是标签,代表一个地址,所以,这里同6,二进制代码也同6
8.这句话是错误的,jmp不支持立即数!
ljmp
ljmp的含义是长跳,长跳主要就是重新加载寄存器,32位保护模式主要体现在段寄存器,具有可以参考段选择子和段描述符的概念,如果不用长跳的话,那么段寄存器不会重新加载,后面的取指结果仍然是老段寄存器中的值,当然保护模式不会生效了,Intel手册上有讲可见寄存器和不可见寄存器的篇章,可以看一下,其实实模式就是保护模式的一种权限全开放的特殊情况,就是说段寄存器左移相当于右边添加0,而这添加的0可以看做保护模式的RPL,RPL为0代表Intel的0环,当然是全权限了。
不过Intel的实模式的概念实属不得已而为之,现在的意义已经不大了,从实模式启动然后跳转到保护模式纯粹是在绕圈子,没有实质的意义,商业上为了保护以前的投资不得不将技术做的没有意义的复杂…
pushf和popf
pushf 的功能是将标志寄存器的值压栈,而 popf 是从栈中弹出数据,输出标志寄存器的值。
具体地说
pushf:指令将标志寄存器的内容压入堆栈,同时栈顶指针SP减2,这条指令可用来保存全部标志位。
popf:指令将栈顶字单元内容送标志寄存器,同时栈顶指针SP加2。
